

日本の製造業AIにおける“データ不足”を解決し
複雑な図面・フロー図の理解を可能に
国産生成AI基盤の独自開発およびビジネス向け生成AIサービスを提供するストックマーク株式会社(本社:東京都港区、代表取締役CEO:林 達、以下:ストックマーク)は、現在開発中の製造業に特化した視覚言語モデル(Vision-Language Model:VLM)において、NVIDIAが提供する日本語ペルソナ合成データセット「Nemotron-Personas-Japan」を活用していることを発表しました。
本取り組みにより、日本の製造業特有の複雑なドキュメントや現場文脈を理解できるAIモデルの開発を加速し、生成AIの実務活用を推進します。
製造業AIの課題「ドキュメント理解」とデータ不足
近年、生成AIの企業活用は急速に進んでいます。しかし製造業分野では、AIによるドキュメント理解が大きな課題となっています。製造現場では次のような資料が日常的に使用されています。
- 工場の工程フロー図
- 設計図面
- 安全管理資料
- 技術仕様書
- 複雑なチャートや設備配置図
これらは単なる文字情報ではなく、「現場特有の専門知識」「機器名称や規格」「日本独自の安全基準」「業務上の文脈」などを理解しなければ正しく解釈することができません。従来、このような画像データに対する教師データ(説明文・アノテーション)を人手で作成するには膨大なコストと時間が必要であり、数年単位のプロジェクトになるケースも少なくありません。また、海外ベースの汎用VLMでは、日本の製造現場特有の業務習慣や専門用語を正確に捉えきれないという課題がありました。
NVIDIA「Nemotron-Personas-Japan」を活用した合成データ生成
ストックマークは、この課題を解決するために、NVIDIAが提供する合成データ生成ワークフロー「Nemotron-Personas-Japan」を活用しました。Nemotron-Personas-Japanは、地域ごとの言語や文化、実世界の文脈を反映したAI開発を支援するためのオープンなペルソナ合成データセットです。このコレクションには日本のほか、
| 米国 |
| インド |
| ブラジル |
| シンガポール |
| フランス |
など各地域のデータセットが含まれており、AI開発者がローカル文化に適したAIシステムを構築できる環境を提供しています。同データセットでは、統計的に設計された合成ペルソナ(人格・役割)を用いて、現実に近いトレーニングデータを生成することが可能です。
250万件の学習データを構築、約半数を合成データで生成
今回のVLM開発では、合計250万件の学習データセットが構築され、そのうち約半数の教師データをNemotron-Personas-Japanによる合成データで生成しました。
このアプローチにより、「人手では数年を要するデータ作成を短期間で実現」「多様な専門視点を含む高品質データを生成」「日本語表現の自然さと実務適合性を向上」といった成果を実現しました。
日本独自の製造現場の文脈をAIへ学習
Nemotron-Personas-Japanの活用により、日本企業特有の業務環境や文化を反映したデータ生成が可能になりました。具体的には、「日本の商習慣」「現場規律」「製造工程の専門用語」「安全基準」などを踏まえた自然な日本語データをAIに学習させることが可能になりました。これにより、日本の企業環境に適したAI応答精度を実現しています。
熟練工・安全管理者など多様なペルソナを再現
Nemotron-Personas-Japanでは、さまざまな職種の専門ペルソナを設定してデータ生成が可能です。ストックマークのVLM開発では、例えば以下のような役割を仮想生成しました。
| 熟練工 |
| 安全管理者 |
| 機械設計部門のベテランエンジニア |
| 品質管理担当者 |
| 生産管理担当者 |
それぞれの視点から画像や図面に対して説明文を生成することで、製造業特有の知識や現場文脈を含む高品質な教師データを構築しています。これにより、日本のビジネス文書特有の複雑な表現や形式を維持しながら、多様な日本語データの大量生成が可能になりました。
▼Nemotron-Personas-Japanを活用して生成したデータサンプル
ストックマークのAIソリューション
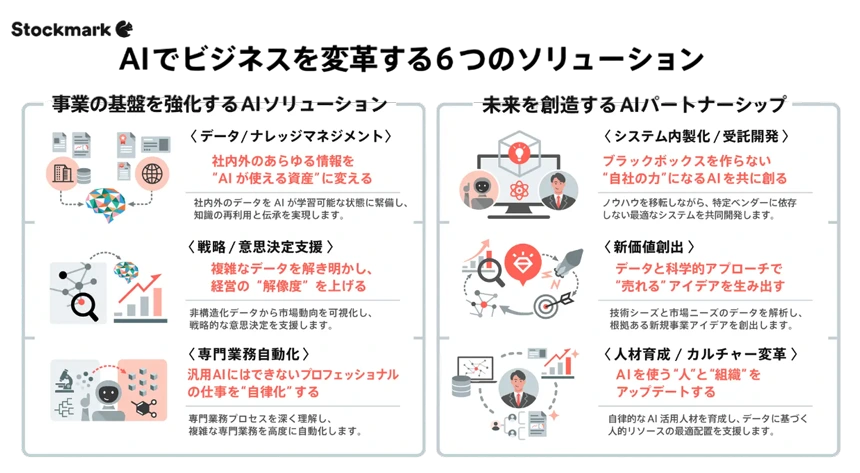
AI活用は企業競争力を維持するための重要な要素となっています。しかし多くの企業が以下の課題に直面しています。
「データが整備されていない」
「AIが現場に定着しない」
「実際の業務成果につながらない」
ストックマークはこれらの課題を解決するため、企業のAI活用を包括的に支援するソリューションを提供しています。
主なサービスには以下があります。
■ Aconnect
製造業向けのAIエージェント。
技術文書や社内情報を横断的に理解し、業務効率化を支援します。
■ SAT(Stockmark AI Technology)
企業内外の膨大なデータを構造化し、企業の知識資産として活用できるプラットフォーム。さらに、企業ごとの業務に最適化した企業特化型生成AIの開発やシステム構築支援も行っています。
ストックマーク株式会社について
ストックマーク株式会社は「価値創造の仕組みを再発明し、人類を前進させる」をミッションに掲げ、最先端の生成AI技術を活用した企業変革を支援しています。製造業をはじめとしたさまざまな業界に対し、AIを活用したナレッジマネジメントや業務効率化を推進しています。
会社概要
| 項目 | 内容 |
|---|---|
| 会社名 | ストックマーク株式会社 |
| 所在地 | 東京都港区南青山一丁目12番3号 LIFORK MINAMI AOYAMA S209 |
| 設立 | 2016年11月15日 |
| 代表者 | 代表取締役CEO 林 達 |
| 事業内容 | 生成AI技術を活用したナレッジマネジメント支援および企業向けAIサービスの開発・運営 |
| URL | https://stockmark.co.jp/ |
記事要約(Summary)
ストックマーク株式会社は、製造業特化の視覚言語モデル(VLM)開発において、NVIDIAの日本語ペルソナ合成データセット「Nemotron-Personas-Japan」を活用していることを発表しました。250万件の学習データのうち約半数を合成データで構築することで、従来は数年かかるデータ作成を大幅に短縮。熟練工や安全管理者などの専門ペルソナを再現した教師データにより、日本の製造現場特有の文脈を理解するAIモデルの開発を実現しました。
本取り組みにより、製造業におけるAI活用の高度化と、生成AIの実業務への導入がさらに加速することが期待されています。
■プレスリリース配信元-ストックマーク株式会社
https://companydata.tsujigawa.com/company/8011801032561/



















この記事へのコメントはありません。